Gradient Boosting: Skforecast, XGBoost, LightGBM y CatBoost
Introducción
Los modelos gradient boosting destacan dentro de la comunidad de machine learning debido a su capacidad para lograr excelentes resultados en una amplia variedad de casos de uso, incluyendo tanto la regresión como la clasificación. Aunque su uso en el forecasting de series temporales ha sido limitado, también pueden conseguir resultados muy competitivos en este ámbito. Algunas de las ventajas que presentan los modelos gradient boosting para forecasting son:
La facilidad con que pueden incorporarse al modelo variables exógenas, además de las autorregresivas.
La capacidad de capturar relaciones no lineales entre variables.
Alta escalabilidad, que permite a los modelos manejar grandes volúmenes de datos.
Algunas implementaciones permiten la inclusión de variables categóricas sin necesidad de codificación adicional, como la codificación one-hot.
A pesar de estas ventajas, el uso de modelos de machine learning para forecasting presenta varios retos que pueden hacer que el analista sea reticente a su uso, los principales son:
Reestructurar los datos para poder utilizarlos como si se tratara de un problema de regresión.
Dependiendo de cuántas predicciones futuras se necesiten (horizonte de predicción), puede ser necesario implementar un proceso iterativo en el que cada nueva predicción se base en las anteriores.
La validación de los modelos requiere de estrategias específicas como backtesting, walk-forward validation o time series cross-validation. No puede aplicarse la validación cruzada tradicional.
La librería skforecast ofrece soluciones automatizadas a estos retos, facilitando el uso y la validación de modelos de machine learning en problemas de forecasting. Skforecast es compatible con las implementaciones de gradient boosting más avanzadas, incluyendo XGBoost, LightGBM, Catboost y HistGradientBoostingRegressor. Este documento muestra cómo utilizarlos para construir modelos de forecasting precisos.
Para garantizar una experiencia de aprendizaje fluida, se realiza una exploración inicial de los datos. A continuación, se explica paso a paso el proceso de modelización, empezando por un modelo recursivo que utiliza un regresor LightGBM y pasando por un modelo que incorpora variables exógenas y diversas estrategias de codificación. El documento concluye demostrando el uso de otras implementaciones de modelos de gradient boosting, como XGBoost, CatBoost y el HistGradientBoostingRegressor de scikit-learn.
Caso de uso
Los sistemas de bicicletas compartidas, también conocidos como sistemas de bicicletas públicas, facilitan la disponibilidad automática de bicicletas para que sean utilizadas temporalmente como medio de transporte. La mayoría de estos sistemas permiten recoger una bicicleta y devolverla en un punto diferente (estaciones o dockers), para que el usuario solo necesite tener la bicicleta en su posesión durante el desplazamiento. Uno de los principales retos en la gestión de estos sistemas es la necesidad de redistribuir las bicicletas para intentar que, en todas las estaciones, haya bicicletas disponibles a la vez que espacios libres para devoluciones.
Con el objetivo de mejorar la planificación y ejecución de la distribución de las bicicletas, se plantea crear un modelo capaz de predecir el número de usuarios para las siguientes 36 horas. De esta forma, a las 12h de cada día, la compañía encargada de gestionar las estaciones de alquiler podrá conocer la demanda prevista el resto del día (12 horas) y el siguiente día (24 horas).
A efectos ilustrativos, el ejemplo actual sólo modela una estación, sin embargo, el modelo puede ampliarse para cubrir múltiples estaciones utilizando global multi-series forecasting, mejorando así la gestión de los sistemas de bicicletas compartidas a mayor escala.
C:\Users\WINDOWS 11\Documents\.virtualenvs\r-tensorflow\lib\site-packages\tqdm\auto.py:21: TqdmWarning:
IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
Datos
Los datos empleados en este documento representan el uso, a nivel horario, del sistema de alquiler de bicicletas en la ciudad de Washington D.C. durante los años 2011 y 2012. Además del número de usuarios por hora, se dispone de información sobre las condiciones meteorológicas y sobre los días festivos. Los datos originales se han obtenido del UCI Machine Learning Repository y han sido procesados previamente (código) aplicando las siguientes modificaciones :
Columnas renombradas con nombres más descriptivos.
Categorías de la variable meteorológica renombradas. La categoría de heavy rain, se ha combinado con la de rain.
Variables de temperatura, humedad y viento desnormalizadas.
Creada variable date_time y establecida como índice.
Imputación de valores missing mediante forward fill.
# Descarga de datos# ==============================================================================datos = fetch_dataset('bike_sharing', raw=True)
bike_sharing
------------
Hourly usage of the bike share system in the city of Washington D.C. during the
years 2011 and 2012. In addition to the number of users per hour, information
about weather conditions and holidays is available.
Fanaee-T,Hadi. (2013). Bike Sharing Dataset. UCI Machine Learning Repository.
https://doi.org/10.24432/C5W894.
Shape of the dataset: (17544, 12)
# Preprocesado de datos (estableciendo índice y frecuencia)# ==============================================================================datos = datos[['date_time', 'users', 'holiday', 'weather', 'temp', 'atemp', 'hum', 'windspeed']]datos['date_time'] = pd.to_datetime(datos['date_time'], format='%Y-%m-%d %H:%M:%S')datos = datos.set_index('date_time')if pd.__version__ <'2.2': datos = datos.asfreq('H')else: datos = datos.asfreq('h')datos = datos.sort_index()datos.head()
users
holiday
weather
temp
atemp
hum
windspeed
date_time
2011-01-01 00:00:00
16.0
0.0
clear
9.84
14.395
81.0
0.0
2011-01-01 01:00:00
40.0
0.0
clear
9.02
13.635
80.0
0.0
2011-01-01 02:00:00
32.0
0.0
clear
9.02
13.635
80.0
0.0
2011-01-01 03:00:00
13.0
0.0
clear
9.84
14.395
75.0
0.0
2011-01-01 04:00:00
1.0
0.0
clear
9.84
14.395
75.0
0.0
# Separación de datos en entrenamiento, validación y test# ==============================================================================fin_train ='2012-04-30 23:59:00'fin_validacion ='2012-08-31 23:59:00'datos_train = datos.loc[: fin_train, :]datos_val = datos.loc[fin_train:fin_validacion, :]datos_test = datos.loc[fin_validacion:, :]print(f"Fechas train : {datos_train.index.min()} --- {datos_train.index.max()} "f"(n={len(datos_train)})")print(f"Fechas validación : {datos_val.index.min()} --- {datos_val.index.max()} "f"(n={len(datos_val)})")print(f"Fechas test : {datos_test.index.min()} --- {datos_test.index.max()} "f"(n={len(datos_test)})")
La exploración gráfica de series temporales es una forma eficaz de identificar tendencias, patrones y variaciones estacionales. Esto, a su vez, ayuda a orientar la selección del modelo de forecasting más adecuado.
Representación de la serie temporal
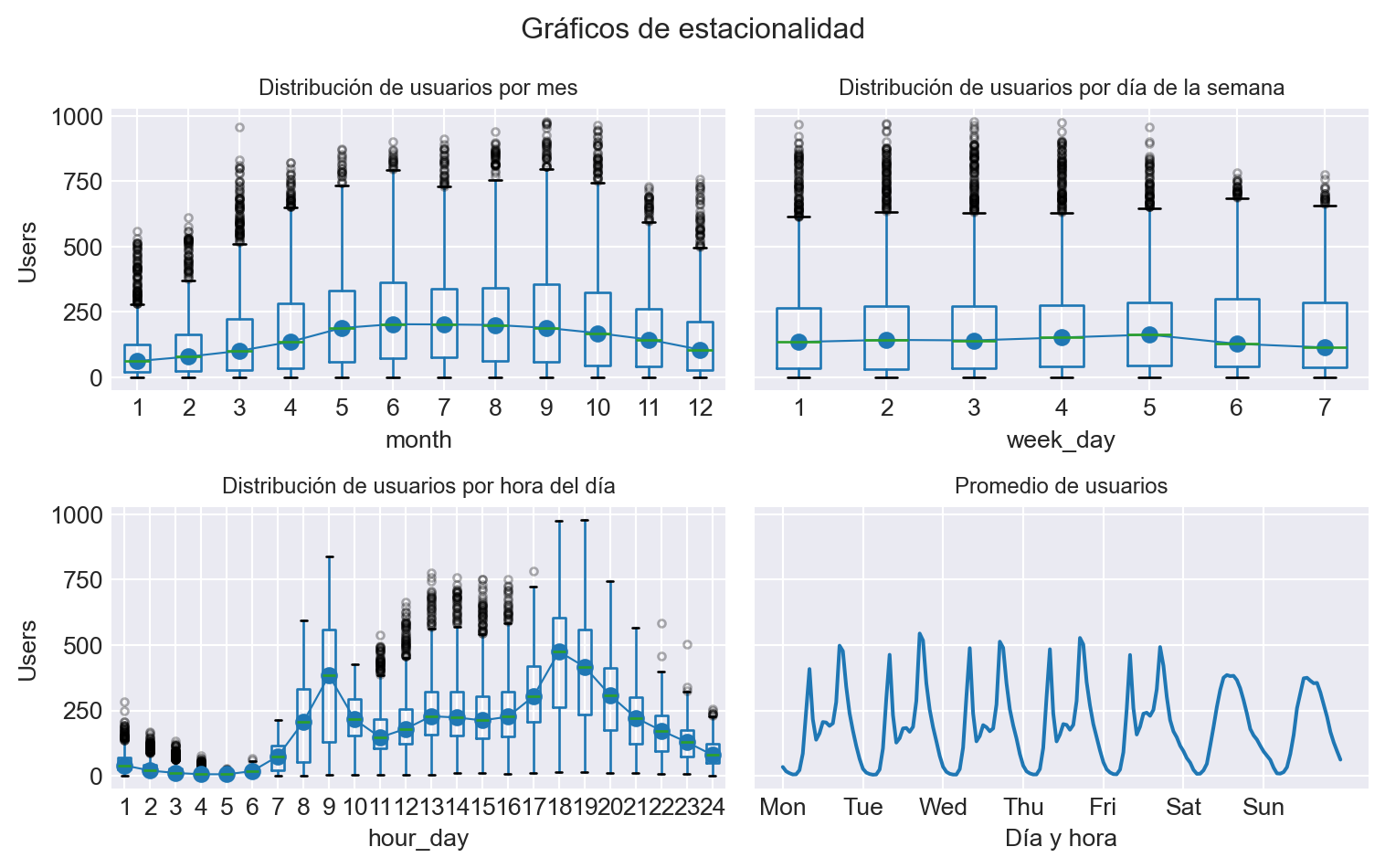
Gráficos de estacionalidad
Los gráficos estacionales son una herramienta útil para identificar patrones y tendencias estacionales en una serie temporal. Se crean promediando los valores de cada estación a lo largo del tiempo y luego trazándolos en función del tiempo.
# Estacionalidad anual, semanal y diaria# ==============================================================================fig, axs = plt.subplots(2, 2, figsize=(8, 5), sharex=False, sharey=True)axs = axs.ravel()# Distribusión de usuarios por mesdatos['month'] = datos.index.monthdatos.boxplot(column='users', by='month', ax=axs[0], flierprops={'markersize': 3, 'alpha': 0.3})datos.groupby('month')['users'].median().plot(style='o-', linewidth=0.8, ax=axs[0])axs[0].set_ylabel('Users')axs[0].set_title('Distribución de usuarios por mes', fontsize=9)# Distribusión de usuarios por día de la semanadatos['week_day'] = datos.index.day_of_week +1datos.boxplot(column='users', by='week_day', ax=axs[1], flierprops={'markersize': 3, 'alpha': 0.3})datos.groupby('week_day')['users'].median().plot(style='o-', linewidth=0.8, ax=axs[1])axs[1].set_ylabel('Users')axs[1].set_title('Distribución de usuarios por día de la semana', fontsize=9)# Distribusión de usuarios por hora del díadatos['hour_day'] = datos.index.hour +1datos.boxplot(column='users', by='hour_day', ax=axs[2], flierprops={'markersize': 3, 'alpha': 0.3})datos.groupby('hour_day')['users'].median().plot(style='o-', linewidth=0.8, ax=axs[2])axs[2].set_ylabel('Users')axs[2].set_title('Distribución de usuarios por hora del día', fontsize=9)# Distribusión de usuarios por día de la semana y hora del díamean_day_hour = datos.groupby(["week_day", "hour_day"])["users"].mean()mean_day_hour.plot(ax=axs[3])axs[3].set( title ="Promedio de usuarios", xticks = [i *24for i inrange(7)], xticklabels = ["Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun"], xlabel ="Día y hora", ylabel ="Users")axs[3].title.set_size(9)fig.suptitle("Gráficos de estacionalidad", fontsize=12)fig.tight_layout()plt.show()
Existe una clara diferencia entre los días entre semana y el fin de semana. También se observa un claro patrón intradiario, con diferente afluencia de usuarios dependiendo de la hora del día.
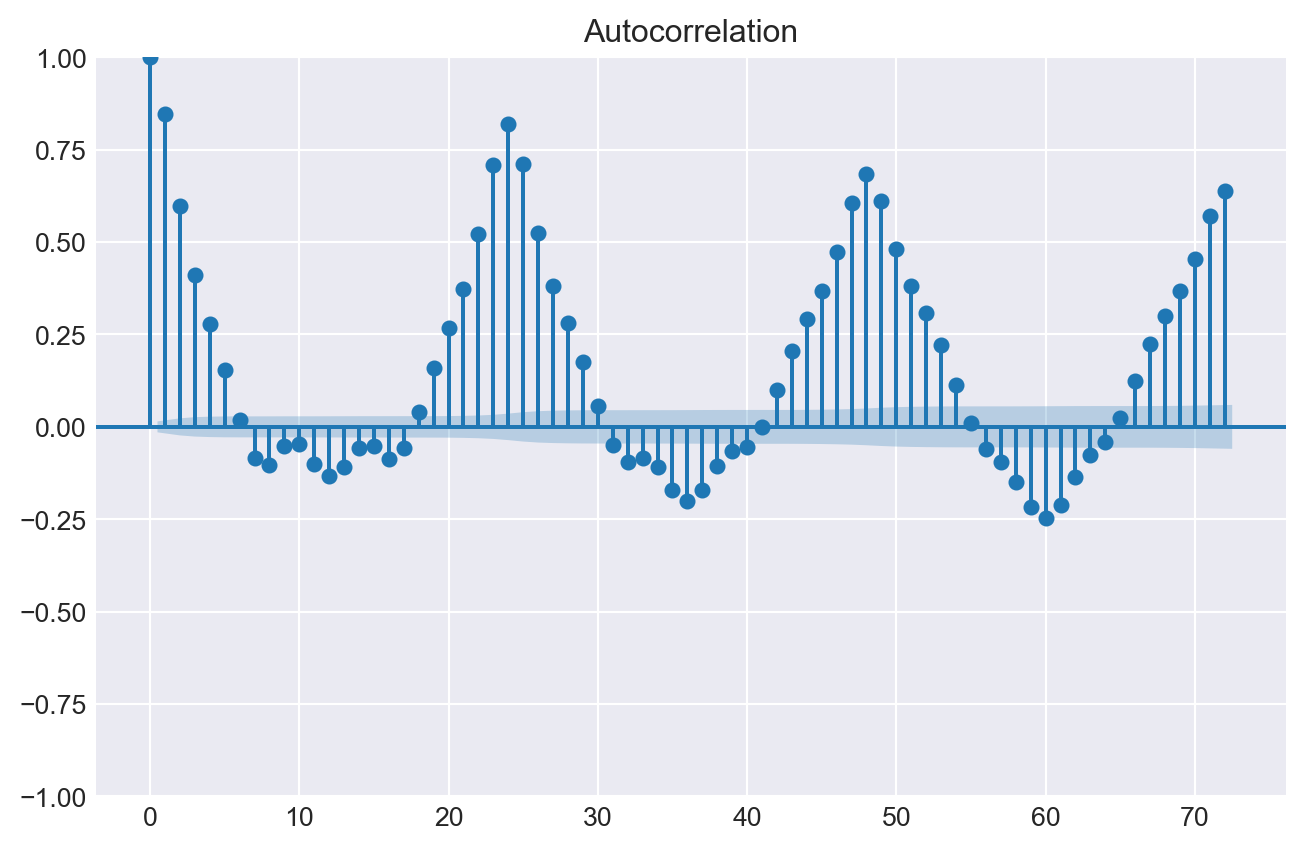
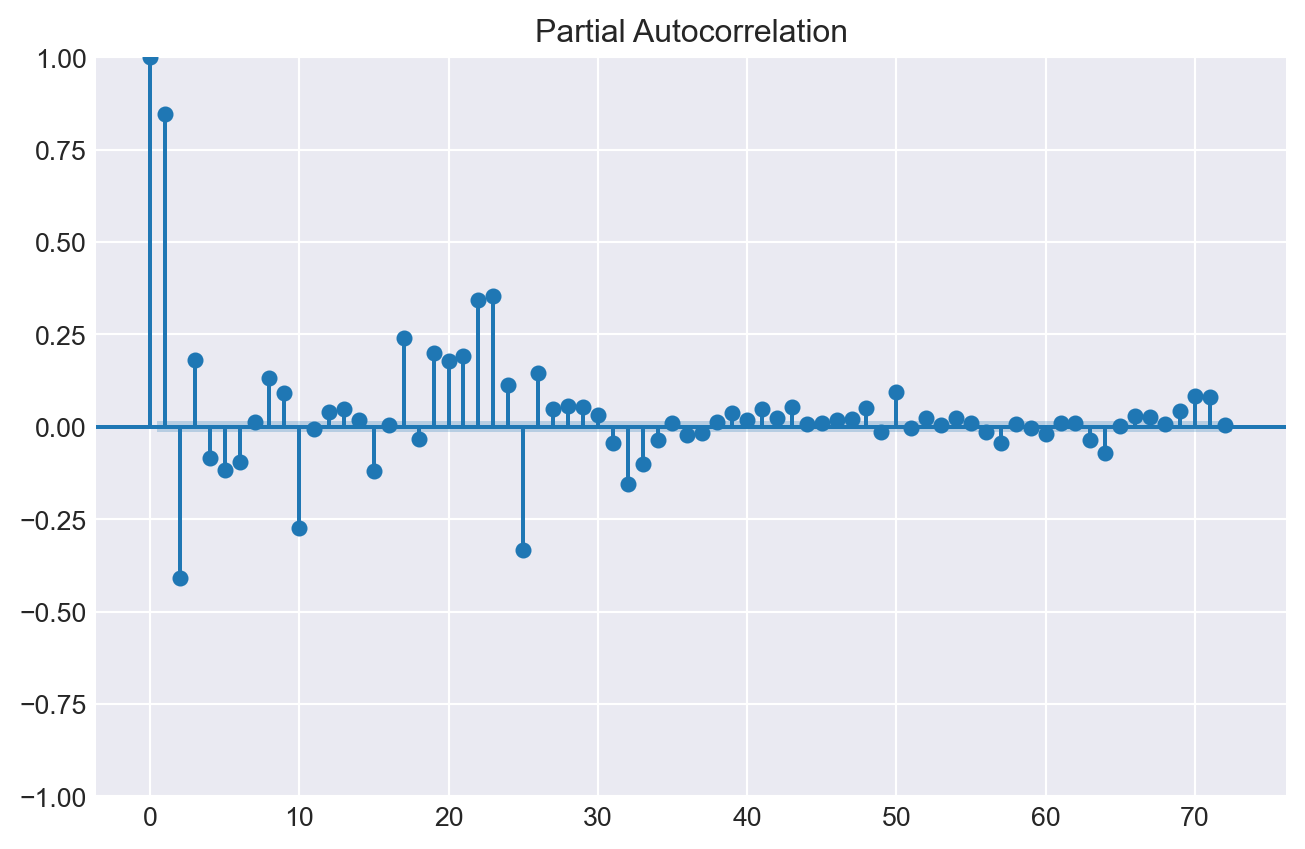
Gráficos de autocorrelación
Los gráficos de autocorrelación muestran la correlación entre una serie temporal y sus valores pasados. Son una herramienta útil para identificar el orden de un modelo autorregresivo, es decir, los valores pasados (lags) que se deben incluir en el modelo.
La función de autocorrelación (ACF) mide la correlación entre una serie temporal y sus valores pasados. La función de autocorrelación parcial (PACF) mide la correlación entre una serie temporal y sus valores pasados, pero solo después de eliminar las variaciones explicadas por los valores pasados intermedios.
# Top 10 lags con mayor autocorrelación parcial absoluta# ==============================================================================calculate_lag_autocorrelation( data = datos['users'], n_lags =60, sort_by ="partial_autocorrelation_abs").head(10)
lag
partial_autocorrelation_abs
partial_autocorrelation
autocorrelation_abs
autocorrelation
0
1
0.845220
0.845220
0.845172
0.845172
1
2
0.408349
-0.408349
0.597704
0.597704
2
23
0.355669
0.355669
0.708470
0.708470
3
22
0.343601
0.343601
0.520804
0.520804
4
25
0.332366
-0.332366
0.711256
0.711256
5
10
0.272649
-0.272649
0.046483
-0.046483
6
17
0.241984
0.241984
0.057267
-0.057267
7
19
0.199286
0.199286
0.159897
0.159897
8
21
0.193404
0.193404
0.373666
0.373666
9
3
0.182068
0.182068
0.409680
0.409680
Los resultados del estudio de autocorrelación indican una correlación significativa entre el número de usuarios en las horas anteriores, así como en los días previos. Esto significa que conocer del número de usuarios durante periodos específicos del pasado proporciona información útil para predecir el número de usuarios en el futuro.
Baseline
Al enfrentarse a un problema de forecasting, es recomendable disponer de un modelo de referencia (baseline). Se trata de un modelo muy sencillo que puede utilizarse como referencia para evaluar si merece la pena aplicar modelos más complejos.
Skforecast permite crear fácilmente un modelo de referencia con su clase ForecasterEquivalentDate. Este modelo, también conocido como Seasonal Naive Forecasting, simplemente devuelve el valor observado en el mismo periodo de la temporada anterior (por ejemplo, el mismo día laboral de la semana anterior, la misma hora del día anterior, etc.).
A partir del análisis exploratorio realizado, el modelo de referencia será el que prediga cada hora utilizando el valor de la misma hora del día anterior.
# Crear un baseline: valor de la misma hora del día anterior# ==============================================================================forecaster = ForecasterEquivalentDate( offset = pd.DateOffset(days=1), n_offsets =1 )# Entremaiento del forecaster# ==============================================================================forecaster.fit(y=datos.loc[:fin_validacion, 'users'])forecaster
========================
ForecasterEquivalentDate
========================
Offset: <DateOffset: days=1>
Number of offsets: 1
Aggregation function: mean
Window size: 24
Series name: users
Training range: [Timestamp('2011-01-01 00:00:00'), Timestamp('2012-08-31 23:00:00')]
Training index type: DatetimeIndex
Training index frequency: h
Creation date: 2025-05-29 11:46:28
Last fit date: 2025-05-29 11:46:28
Skforecast version: 0.16.0
Python version: 3.10.11
Forecaster id: None
El MAE del modelo baseline se utiliza como referencia para evaluar si merece la pena aplicar los modelos más complejos.
Forecasting con con LightGBM
LightGBM es una implementación altamente eficiente del algoritmo gradient boosting, que se ha convertido en un referente en el campo del machine learning. La librería LightGBM incluye su propia API, así como la API de scikit-learn, lo que la hace compatible con skforecast.
En primer lugar, se entrena un modelo ForecasterAutoreg utilizando valores pasados de la variable de respuesta (lags) y la media movil como predictores. Posteriormente, se añaden variables exógenas al modelo y se evalúa la mejora de su rendimiento. Dado que los modelos de Gradient Boosting tienen un gran número de hiperparámetros, se realiza una Búsqueda Bayesiana utilizando la función bayesian_search_forecaster() para encontrar la mejor combinación de hiperparámetros y lags. Por último, se evalúa la capacidad predictiva del modelo mediante un proceso de backtesting.
Para obtener una estimación robusta de la capacidad predictiva del modelo, se realiza un proceso de backtesting. El proceso de backtesting consiste en generar una predicción para cada observación del conjunto de test, siguiendo el mismo procedimiento que se seguiría si el modelo estuviese en producción, y finalmente comparar el valor predicho con el valor real.
Se recomienda revisar la documentación de la función backtesting_forecaster para comprender mejor sus capacidades. Esto ayudará a utilizar todo su potencial para analizar la capacidad predictiva del modelo.
# Backtest del modelo con lo datos de test# ==============================================================================cv = TimeSeriesFold(steps =36, initial_train_size =len(datos.loc[:fin_validacion]))metrica, predicciones = backtesting_forecaster( forecaster = forecaster, y = datos['users'], cv = cv, metric ='mean_absolute_error' )predicciones.head()# Error de backtest# ==============================================================================metrica
El error de predicción del modelo autorregresivo alcanza un MAE inferior al del modelo de referencia.
Variables exógenas
Hasta ahora, sólo se han utilizado como predictores los valores pasados (lags) de la serie temporal. Sin embargo, es posible incluir otras variables como predictores. Estas variables se conocen como variables exógenas (features) y su uso puede mejorar la capacidad predictiva del modelo. Un punto muy importante que hay que tener en cuenta es que los valores de las variables exógenas deben conocerse en el momento de la predicción.
Ejemplos habituales de variables exógenas son aquellas obtenidas del calendario, como el día de la semana, el mes, el año o los días festivos. Las variables meteorológicas como la temperatura, la humedad y el viento también entran en esta categoría, al igual que las variables económicas como la inflación y los tipos de interés.
Variables de calendario y meteorológicas
A continuación, se crean variables exógenas basadas en información del calendario, las horas de salida y puesta del sol, la temperatura y los días festivos. Estas nuevas variables se añaden a los conjuntos de entrenamiento, validación y test, y se utilizan como predictores en el modelo autorregresivo.
# Variables basadas en el calendario# ==============================================================================features_to_extract = ['month','week','day_of_week','hour']calendar_transformer = DatetimeFeatures( variables ='index', features_to_extract = features_to_extract, drop_original =True,)variables_calendario = calendar_transformer.fit_transform(datos)[features_to_extract]# Variables basadas en la luz solar# ==============================================================================location = LocationInfo( name ='Washington DC', region ='USA', timezone ='US/Eastern', latitude =40.516666666666666, longitude =-77.03333333333333)sunrise_hour = [ sun(location.observer, date=date, tzinfo=location.timezone)['sunrise'].hourfor date in datos.index]sunset_hour = [ sun(location.observer, date=date, tzinfo=location.timezone)['sunset'].hourfor date in datos.index]variables_solares = pd.DataFrame({'sunrise_hour': sunrise_hour,'sunset_hour': sunset_hour}, index = datos.index )variables_solares['daylight_hours'] = ( variables_solares['sunset_hour'] - variables_solares['sunrise_hour'])variables_solares["is_daylight"] = np.where( (datos.index.hour >= variables_solares["sunrise_hour"])& (datos.index.hour < variables_solares["sunset_hour"]),1,0,)# Variables basadas en festivos# ==============================================================================variables_festivos = datos[['holiday']].astype(int)variables_festivos['holiday_previous_day'] = variables_festivos['holiday'].shift(24)variables_festivos['holiday_next_day'] = variables_festivos['holiday'].shift(-24)# Variables basadas en temperatura# ==============================================================================wf_transformer = WindowFeatures( variables = ["temp"], window = ["1D", "7D"], functions = ["mean", "max", "min"], freq ="h",)variables_temp = wf_transformer.fit_transform(datos[['temp']])# Unión de variables exógenas# ==============================================================================assertall(variables_calendario.index == variables_solares.index)assertall(variables_calendario.index == variables_festivos.index)assertall(variables_calendario.index == variables_temp.index)variables_exogenas = pd.concat([ variables_calendario, variables_solares, variables_temp, variables_festivos], axis=1)# Debido a la creación de medias móviles, hay valores faltantes al principio# de la serie. Y debido a holiday_next_day hay valores faltantes al final.variables_exogenas = variables_exogenas.iloc[7*24:, :]variables_exogenas = variables_exogenas.iloc[:-24, :]variables_exogenas.head(3)
month
week
day_of_week
hour
sunrise_hour
sunset_hour
daylight_hours
is_daylight
temp
temp_window_1D_mean
temp_window_1D_max
temp_window_1D_min
temp_window_7D_mean
temp_window_7D_max
temp_window_7D_min
holiday
holiday_previous_day
holiday_next_day
date_time
2011-01-08 00:00:00
1
1
5
0
7
16
9
0
7.38
8.063333
9.02
6.56
10.127976
18.86
4.92
0
0.0
0.0
2011-01-08 01:00:00
1
1
5
1
7
16
9
0
7.38
8.029167
9.02
6.56
10.113333
18.86
4.92
0
0.0
0.0
2011-01-08 02:00:00
1
1
5
2
7
16
9
0
7.38
7.995000
9.02
6.56
10.103571
18.86
4.92
0
0.0
0.0
Variables con patrones cíclicos
Algunos aspectos del calendario, como las horas o los días, son cíclicos. Por ejemplo, la hora del día va de 0 a 23 horas. Este tipo de variables pueden tratarse de varias formas, cada una con sus ventajas e inconvenientes.
Un enfoque consiste en utilizar las variables directamente como valores numéricos sin ninguna transformación. Este método evita crear variables nuevas, pero puede imponer un orden lineal incorrecto a los valores. Por ejemplo, la hora 23 de un día y la hora 00 del siguiente están muy alejadas en su representación lineal, cuando en realidad sólo hay una hora de diferencia entre ellas.
Otra posibilidad es tratar las variables cíclicas como variables categóricas para evitar imponer un orden lineal. Sin embargo, este enfoque puede provocar la pérdida de la información cíclica inherente a la variable.
Existe una tercera forma de tratar las variables cíclicas que suele preferirse a los otros dos métodos. Se trata de transformar las variables utilizando el seno y el coseno de su periodo. Este método genera solo dos nuevas variables que captan la ciclicidad de los datos con mayor precisión que los dos métodos anteriores, ya que preserva el orden natural de la variable y evita imponer un orden lineal.
# Codificación cíclica de las variables de calendario y luz solar# ==============================================================================features_to_encode = ["month","week","day_of_week","hour","sunrise_hour","sunset_hour",]max_values = {"month": 12,"week": 52,"day_of_week": 7,"hour": 24,"sunrise_hour": 24,"sunset_hour": 24,}cyclical_encoder = CyclicalFeatures( variables = features_to_encode, max_values = max_values, drop_original =False)variables_exogenas = cyclical_encoder.fit_transform(variables_exogenas)variables_exogenas.head(3)
month
week
day_of_week
hour
sunrise_hour
sunset_hour
daylight_hours
is_daylight
temp
temp_window_1D_mean
...
week_sin
week_cos
day_of_week_sin
day_of_week_cos
hour_sin
hour_cos
sunrise_hour_sin
sunrise_hour_cos
sunset_hour_sin
sunset_hour_cos
date_time
2011-01-08 00:00:00
1
1
5
0
7
16
9
0
7.38
8.063333
...
0.120537
0.992709
-0.974928
-0.222521
0.000000
1.000000
0.965926
-0.258819
-0.866025
-0.5
2011-01-08 01:00:00
1
1
5
1
7
16
9
0
7.38
8.029167
...
0.120537
0.992709
-0.974928
-0.222521
0.258819
0.965926
0.965926
-0.258819
-0.866025
-0.5
2011-01-08 02:00:00
1
1
5
2
7
16
9
0
7.38
7.995000
...
0.120537
0.992709
-0.974928
-0.222521
0.500000
0.866025
0.965926
-0.258819
-0.866025
-0.5
3 rows × 30 columns
Interacción entre variables
En muchos casos, las variables exógenas no son independientes. Más bien, su efecto sobre la variable objetivo depende del valor de otras variables. Por ejemplo, el efecto de la temperatura en la demanda de electricidad depende de la hora del día. La interacción entre las variables exógenas puede captarse mediante nuevas variables que se obtienen multiplicando entre sí las variables existentes. Estas interacciones se obtienen fácilmente con la clase PolynomialFeatures de scikit-learn.
Existen varios enfoques para incorporar variables categóricas en LightGBM (y otras implementaciones de gradient boosting):
Una opción es transformar los datos convirtiendo los valores categóricos en valores numéricos utilizando métodos como la codificación one hot la codificación ordinal. Este enfoque es aplicable a todos los modelos de aprendizaje automático.
LightGBM puede manejar variables categóricas internamente sin necesidad de preprocesamiento. Esto puede hacerse automáticamente estableciendo el parámetro categorical_features='auto' y almacenando las variables con el tipo de dato category dentro de un Pandas DataFrame. Tambien es posible especificar los nombres de las variables a tratar como categóricas pasando una lista de nombres al parámetro categorical_features.
No hay un método que sea siempre mejor que los otros. Las reglas generales son:
Cuando la cardinalidad de las variables categóricas es alta (muchos valores diferentes), es mejor utilizar el soporte nativo para variables categóricas que utilizar la codificación one-hot.
Con datos codificados con one hot encoding, se necesitan más puntos de división (es decir, más profundidad) para recuperar una división equivalente a la que podría obtenerse con un solo punto de división utilizando el tratamiento nativo.
Cuando una variable categórica se convierte en múltiples variables dummy utilizando one hot encoding, su importancia se diluye, haciendo que el análisis de la importancia de las características sea más complejo de interpretar.
# Almacenar las variables categoricas como tipo "category"# ==============================================================================datos["weather"] = datos["weather"].astype("category")
ColumnTransformers en scikit-learn proporcionan una potente forma de definir transformaciones y aplicarlas a variables específicas. Al encapsular las transformaciones en un objeto ColumnTransformer, se puede pasar a un Forecaster utilizando el argumento transformer_exog.
# Transformación con codificación one-hot# ==============================================================================one_hot_encoder = make_column_transformer( ( OneHotEncoder(sparse_output=False, drop='if_binary'), make_column_selector(dtype_include=['category', 'object']), ), remainder="passthrough", verbose_feature_names_out=False,).set_output(transform="pandas") # Crear un forecaster con un transformer para las variables exógenas# ==============================================================================forecaster = ForecasterRecursive( regressor = LGBMRegressor(random_state=15926, verbose=-1), lags =72, transformer_exog = one_hot_encoder )
Para examinar cómo se transforman los datos, se puede utilizar el método create_train_X_y y generar las matrices que el forecaster utiliza para entrenar el modelo. Este método permite conocer las manipulaciones específicas de los datos que se producen durante el proceso de entrenamiento.
La estrategia One Hot Encoder se ha mostrado con fines didácticos. Para el resto del documento, sin embargo, se utiliza el soporte nativo para variables categóricas.
Implementación nativa para variables categóricas
Las librerías de Gradient Boosting (XGBoost, LightGBM, CatBoost y HistGradientBoostingRegressor) asumen que las variables de entrada son números enteros empezando por 0 hasta el número de categorías [0, 1, …, n_categories-1]. En la mayoría de los casos reales, las variables categóricas no se codifican con números sino con cadenas (strings), por lo que es necesario un paso intermedio de transformación. Existen dos opciones:
Asignar a las columnas con variables categóricas el tipo category. Internamente, esta estructura de datos consiste en una matriz de categorías y una matriz de valores enteros (códigos) que apuntan al valor real de la matriz de categorías. Es decir, internamente es una matriz numérica con un mapeo que relaciona cada valor con una categoría. Los modelos son capaces de identificar automáticamente las columnas de tipo category y acceder a sus códigos internos. Este enfoque es aplicable a XGBoost, LightGBM y CatBoost.
Preprocesar las columnas categóricas con un OrdinalEncoder para transformar sus valores a enteros y luego indicar explícitamente que deben ser tratadas como categóricas.
Para utilizar la detección automática en skforecast, las variables categóricas deben codificarse primero como enteros y luego almacenarse de nuevo como tipo category. Esto se debe a que skforecast utiliza internamente una matriz numérica numpy para acelerar el cálculo.
Cuando se utiliza el regresor LightGBM, se tiene que especificar cómo tratar las variables categóricas utilizando el argumento categorical_feature en el método fit(). Esto es debido a que el argumento categorical_feature sólo se puede especificar en el método fit() y no en la inicialización del regresor.
# Crear un forecaster con detección automática de variables categóricas (LGBMRegressor)# ==============================================================================forecaster = ForecasterRecursive( regressor = LGBMRegressor(random_state=15926, verbose=-1), lags =72, transformer_exog = transformer_exog, fit_kwargs = {"categorical_feature": "auto"} )
Evaluar el modelo con variables exógenas
Se entrena de nuevo el forecaster, pero esta vez, las variables exógenas también se incluyen como predictores. Para las variables categóricas, se utiliza la implementación nativa.
# Selección de variables exógenas a incluir en el modelo# ==============================================================================exog_cols = []# Columnas que terminan con _seno o _coseno son seleccionadasexog_cols.extend(variables_exogenas.filter(regex='_sin$|_cos$').columns.tolist())# Columnas que empiezan con tem_ son seleccionadasexog_cols.extend(variables_exogenas.filter(regex='^temp_.*').columns.tolist())# Columnas que empiezan con holiday_ son seleccionadasexog_cols.extend(variables_exogenas.filter(regex='^holiday_.*').columns.tolist())exog_cols.extend(['temp', 'holiday', 'weather'])variables_exogenas = variables_exogenas.filter(exog_cols, axis=1)# Combinar variables exógenas y target en el mismo dataframe# ==============================================================================datos = datos[['users', 'weather']].merge( variables_exogenas, left_index =True, right_index =True, how ='inner'# Para utilizar solo fechas para las que hay datos exógenos )datos = datos.astype({col: np.float32 for col in datos.select_dtypes("number").columns})datos_train = datos.loc[: fin_train, :].copy()datos_val = datos.loc[fin_train:fin_validacion, :].copy()datos_test = datos.loc[fin_validacion:, :].copy()# Backtesting en los datos de test incluyendo las variables exógenas# ==============================================================================cv = TimeSeriesFold(steps =36, initial_train_size =len(datos.loc[:fin_validacion]))metrica, predicciones = backtesting_forecaster( forecaster = forecaster, y = datos['users'], exog = datos[exog_cols], cv = cv, metric ='mean_absolute_error' )metrica
La incorporación de variables exógenas mejora la capacidad predictiva del modelo.
Optimización de hiperparámetros
El ForecasterRecursive entrenado utiliza los primeros 24 lags y un modelo LGMBRegressor con los hiperparámetros por defecto. Sin embargo, no hay ninguna razón por la que estos valores sean los más adecuados. Para encontrar los mejores hiperparámetros, se realiza una Búsqueda Bayesiana con la función bayesian_search_forecaster(). La búsqueda se lleva a cabo utilizando el mismo proceso de backtesting que antes, pero cada vez, el modelo se entrena con diferentes combinaciones de hiperparámetros y lags. Es importante señalar que la búsqueda de hiperparámetros debe realizarse utilizando el conjunto de validación, nunca con los datos de test.
La búsqueda se realiza probando cada combinación de hiperparámetros y retardos del siguiente modo:
Entrenar el modelo utilizando sólo el conjunto de entrenamiento.
El modelo se evalúa utilizando el conjunto de validación mediante backtesting.
Seleccionar la combinación de hiperparámetros y retardos que proporcione el menor error.
Volver a entrenar el modelo con la mejor combinación encontrada, esta vez utilizando tanto los datos de entrenamiento como los de validación.
Siguiendo estos pasos, se puede obtener un modelo con hiperparámetros optimizados y evitar el sobreajuste.
La selección de predictores (feature selection) es el proceso de identificar un subconjunto de predictores relevantes para su uso en la creación del modelo. Es un paso importante en el proceso de machine learning, ya que puede ayudar a reducir el sobreajuste, mejorar la precisión del modelo y reducir el tiempo de entrenamiento. Dado que los regresores subyacentes de skforecast siguen la API de scikit-learn, es posible utilizar los métodos de selección de predictores disponibles en scikit-learn. Dos de los métodos más populares son Recursive Feature Elimination y Sequential Feature Selection.
Recursive feature elimination (RFECV)
-------------------------------------
Total number of records available: 11327
Total number of records used for feature selection: 5663
Number of features available: 99
Lags (n=9)
Window features (n=1)
Exog (n=89)
Number of features selected: 60
Lags (n=9) : [1, 2, 3, 23, 24, 25, 167, 168, 169]
Window features (n=1) : ['roll_mean_72']
Exog (n=50) : ['weather', 'month_sin', 'week_sin', 'week_cos', 'day_of_week_sin', 'hour_sin', 'hour_cos', 'poly_month_sin__week_cos', 'poly_month_sin__day_of_week_sin', 'poly_month_sin__day_of_week_cos', 'poly_month_sin__hour_sin', 'poly_month_sin__hour_cos', 'poly_month_cos__week_sin', 'poly_month_cos__day_of_week_sin', 'poly_month_cos__day_of_week_cos', 'poly_month_cos__hour_sin', 'poly_month_cos__hour_cos', 'poly_week_sin__day_of_week_sin', 'poly_week_sin__day_of_week_cos', 'poly_week_sin__hour_sin', 'poly_week_sin__hour_cos', 'poly_week_sin__sunrise_hour_cos', 'poly_week_cos__day_of_week_sin', 'poly_week_cos__day_of_week_cos', 'poly_week_cos__hour_sin', 'poly_week_cos__hour_cos', 'poly_week_cos__sunrise_hour_cos', 'poly_day_of_week_sin__day_of_week_cos', 'poly_day_of_week_sin__hour_sin', 'poly_day_of_week_sin__hour_cos', 'poly_day_of_week_sin__sunrise_hour_sin', 'poly_day_of_week_sin__sunset_hour_sin', 'poly_day_of_week_cos__hour_sin', 'poly_day_of_week_cos__hour_cos', 'poly_day_of_week_cos__sunset_hour_sin', 'poly_hour_sin__hour_cos', 'poly_hour_sin__sunrise_hour_sin', 'poly_hour_sin__sunrise_hour_cos', 'poly_hour_sin__sunset_hour_sin', 'poly_hour_sin__sunset_hour_cos', 'poly_hour_cos__sunrise_hour_sin', 'poly_hour_cos__sunrise_hour_cos', 'poly_hour_cos__sunset_hour_sin', 'temp_window_1D_mean', 'temp_window_1D_max', 'temp_window_1D_min', 'temp_window_7D_mean', 'temp_window_7D_min', 'temp', 'holiday']
El RFECV de scikit-learn empieza entrenando un modelo con todos los predictores disponibles y calculando la importancia de cada uno en base a los atributos como coef_ o feature_importances_. A continuación, se elimina el predictor menos importante y se realiza una validación cruzada para calcular el rendimiento del modelo con los predictores restantes. Este proceso se repite hasta que la eliminación de predictores adicionales no mejora la metrica de rendimiento elegida o se alcanza el min_features_to_select.
El resultado final es un subconjunto de predictores que idealmente equilibra la simplicidad del modelo y su capacidad predictiva, determinada por el proceso de validación cruzada.
El forecater se entrena y evalúa de nuevo utilizando el conjunto de predictores seleccionados.
# Crear forecaster con los predictores seleccionados# ==============================================================================forecaster = ForecasterRecursive( regressor = LGBMRegressor(**best_params), lags = lags_seleccionados, window_features = window_features, transformer_exog = transformer_exog, fit_kwargs = {"categorical_feature": "auto"})# Backtesting con los predictores seleccionados y los datos de test# ==============================================================================cv = TimeSeriesFold(steps =36, initial_train_size =len(datos[:fin_validacion]))metrica_lgbm, predicciones = backtesting_forecaster( forecaster = forecaster, y = datos['users'], exog = datos[exog_seleccionadas], cv = cv, metric ='mean_absolute_error')metrica_lgbm
El rendimiento del modelo sigue siendo similar al del modelo entrenado con todas las variables. Sin embargo, el modelo es ahora mucho más simple, lo que hará que sea más rápido de entrenar y menos propenso al sobreajuste. Para el resto del documento, el modelo se entrenará utilizando sólo las variables seleccionadas.
# Actualizar las variables exógenas utilizadas# ==============================================================================exog_cols = exog_seleccionadas
Forecasting probabilístico: intervalos de predicción
Un intervalo de predicción define el intervalo dentro del cual es de esperar que se encuentre el verdadero valor de la variable respuesta con una determinada probabilidad. Skforecast implementa varios métodos para el forecasting probabilístico:
El siguiente código muestra cómo generar intervalos de predicción utilizando el método coformal prediction.
Con la función prediction_interval() se predicen los intervalos para los siguientes n step.
Con la función backtesting_forecaster() se predicen los intervalos de todo el conjunto de test.
El argumento interval se utiliza para especificar la probabilidad de cobertura deseada de los intervalos. En este caso, interval se establece en [5, 95], lo que significa una cobertura teórica del 90%.
# Crear y entrenar forecaster# ==============================================================================forecaster = ForecasterRecursive( regressor = LGBMRegressor(**best_params), lags = [1, 2, 3, 23, 24, 25, 167, 168, 169], window_features = window_features, transformer_exog = transformer_exog, fit_kwargs = {"categorical_feature": "auto"}, binner_kwargs = {"n_bins": 5})forecaster.fit( y = datos.loc[:fin_train, 'users'], exog = datos.loc[:fin_train, exog_cols], store_in_sample_residuals =True)# Predicción de intervalos# ==============================================================================# Como el modelo ha sido entrenado con variables exógenas, se tienen que pasar# para las predicciones.predicciones = forecaster.predict_interval( exog = datos.loc[fin_train:, exog_cols], steps =36, interval = [5, 95], method ='conformal',)predicciones.head()
pred
lower_bound
upper_bound
2012-05-01 00:00:00
23.714525
0.062383
47.366666
2012-05-01 01:00:00
8.618651
0.297713
16.939588
2012-05-01 02:00:00
5.222926
-3.098012
13.543864
2012-05-01 03:00:00
5.053190
-3.267748
13.374128
2012-05-01 04:00:00
6.758192
-1.562746
15.079130
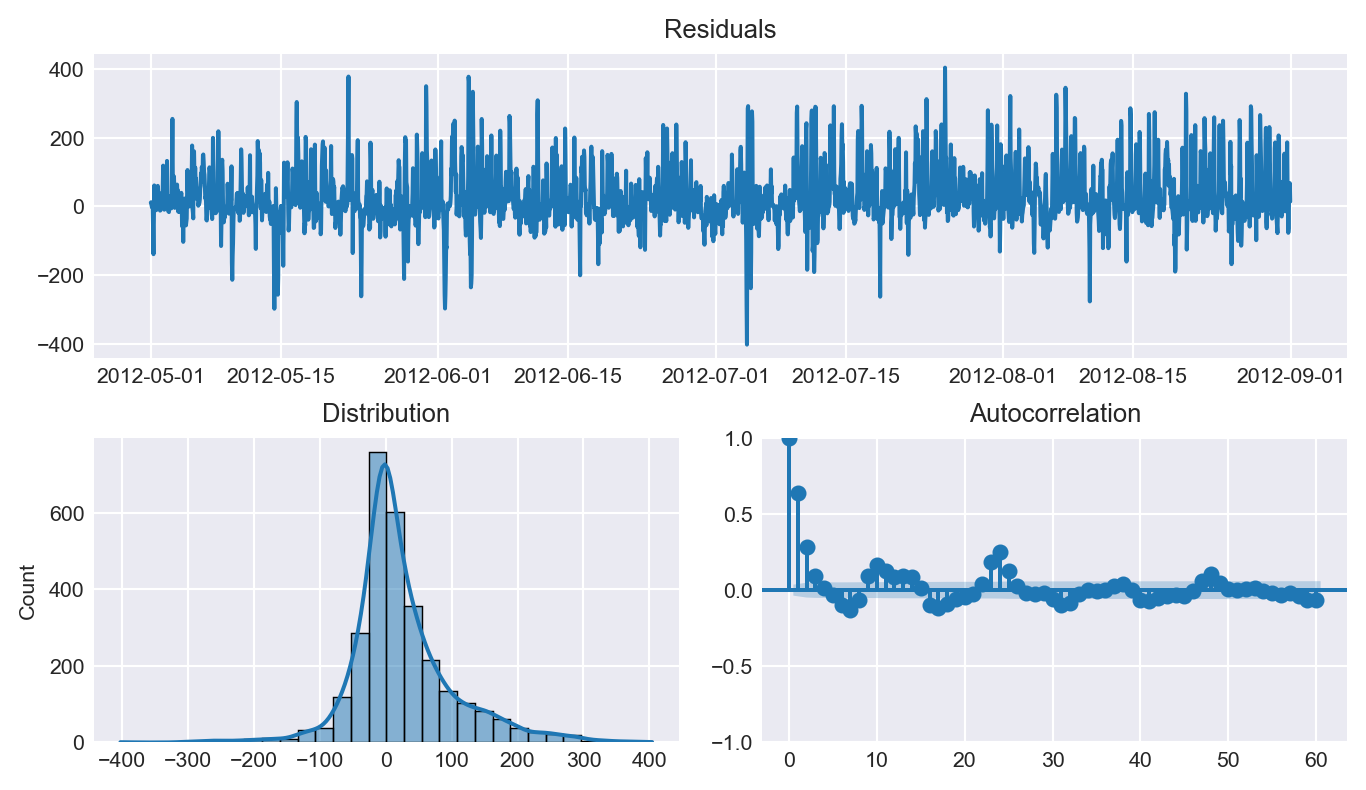
Por defecto, los intervalos se calculan utilizando los residuos in-sample (residuos del conjunto de entrenamiento). Sin embargo, esto puede dar lugar a intervalos demasiado estrechos (demasiado optimistas). Para evitarlo, se utiliza el método set_out_sample_residuals() para almacenar residuos out-sample calculados mediante backtesting con un conjunto de validación.
Si además de los residuos, se le pasan las correspondientes predicciones al método set_out_sample_residuals(), entonces los residuos utilizados en el proceso de bootstrapping se seleccionan condicionados al rango de valores de las predicciones. Esto puede ayudar a conseguir intervalos con mayor covertura a la vez que se mantienen lo más estrechos posibles.
# Backtesting con los datos de validación para obtener residuos out-sample# ==============================================================================cv = TimeSeriesFold(steps =36, initial_train_size =len(datos.loc[:fin_train]))_, predicciones_val = backtesting_forecaster( forecaster = forecaster, y = datos.loc[:fin_validacion, 'users'], exog = datos.loc[:fin_validacion, exog_cols], cv = cv, metric ='mean_absolute_error',)# Distribución de los residuos out-sample# ==============================================================================residuals = datos.loc[predicciones_val.index, 'users'] - predicciones_val['pred']print(pd.Series(np.where(residuals <0, 'negative', 'positive')).value_counts())plt.rcParams.update({'font.size': 8})_ = plot_residuals( y_true = datos.loc[predicciones_val.index, 'users'], y_pred = predicciones_val['pred'], figsize=(7, 4) )# Almacenar residuos out-sample en el forecaster# ==============================================================================forecaster.set_out_sample_residuals( y_true = datos.loc[predicciones_val.index, 'users'], y_pred = predicciones_val['pred'])
A continuación, se ejecuta el proceso de backtesting para estimar los intervalos de predicción en el conjunto de test. Se indica el argumento use_in_sample_residuals en False para que se utilicen los residuos out-sample almacenados previamente y use_binned_residuals para que el los residuos utilizados en se seleccionen condicionados al rango de valores de las predicciones.
# Backtesting con intervalos de predicción en test usando out-sample residuals# ==============================================================================cv = TimeSeriesFold(steps =36, initial_train_size =len(datos.loc[:fin_validacion]))metrica, predicciones = backtesting_forecaster( forecaster = forecaster, y = datos['users'], exog = datos[exog_cols], cv = cv, metric ='mean_absolute_error', interval = [5, 95], # 90% intervalo de predicción interval_method ='conformal', use_in_sample_residuals =False, # Usar out-sample residuals use_binned_residuals =True, # Usar residuos condicionados al valor predicho)predicciones.head(5)# Cobertura del intervalo en los datos de test# ==============================================================================
Debido a la naturaleza compleja de muchos de los actuales modelos de machine learning, a menudo funcionan como cajas negras, lo que dificulta entender por qué han hecho una predicción u otra. Las técnicas de explicabilidad pretenden desmitificar estos modelos, proporcionando información sobre su funcionamiento interno y ayudando a generar confianza, mejorar la transparencia y cumplir los requisitos normativos en diversos ámbitos. Mejorar la explicabilidad de los modelos no sólo ayuda a comprender su comportamiento, sino también a identificar sesgos, mejorar su rendimiento y permitir a las partes interesadas tomar decisiones más informadas basadas en los conocimientos del machine learning
# Crear y entrenar el forecaster# ==============================================================================forecaster = ForecasterRecursive( regressor = LGBMRegressor(**best_params), lags = [1, 2, 3, 23, 24, 25, 167, 168, 169], window_features = window_features, transformer_exog = transformer_exog, fit_kwargs = {"categorical_feature": "auto"})forecaster.fit( y = datos.loc[:fin_validacion, 'users'], exog = datos.loc[:fin_validacion, exog_cols])# Extraer importancia de los predictores# ==============================================================================importancia = forecaster.get_feature_importances()importancia.head(10)
feature
importance
0
lag_1
1012
8
lag_169
568
7
lag_168
556
1
lag_2
365
4
lag_24
358
6
lag_167
344
2
lag_3
325
3
lag_23
311
15
hour_sin
295
16
hour_cos
282
Shap values
Los valores SHAP (SHapley Additive exPlanations) son un método muy utilizado para explicar los modelos de machine learning, ya que ayudan a comprender cómo influyen las variables y los valores en las predicciones de forma visual y cuantitativa.
Se puede obtener un análisis SHAP a partir de modelos skforecast con sólo dos elementos:
El regresor interno del forecaster.
Las matrices de entrenamiento creadas a partir de la serie temporal y variables exógenas, utilizadas para ajustar el pronosticador.
Aprovechando estos dos componentes, los usuarios pueden crear explicaciones interpretables para sus modelos de skforecast. Estas explicaciones pueden utilizarse para verificar la fiabilidad del modelo, identificar los factores más significativos que contribuyen a las predicciones y comprender mejor la relación subyacente entre las variables de entrada y la variable objetivo.
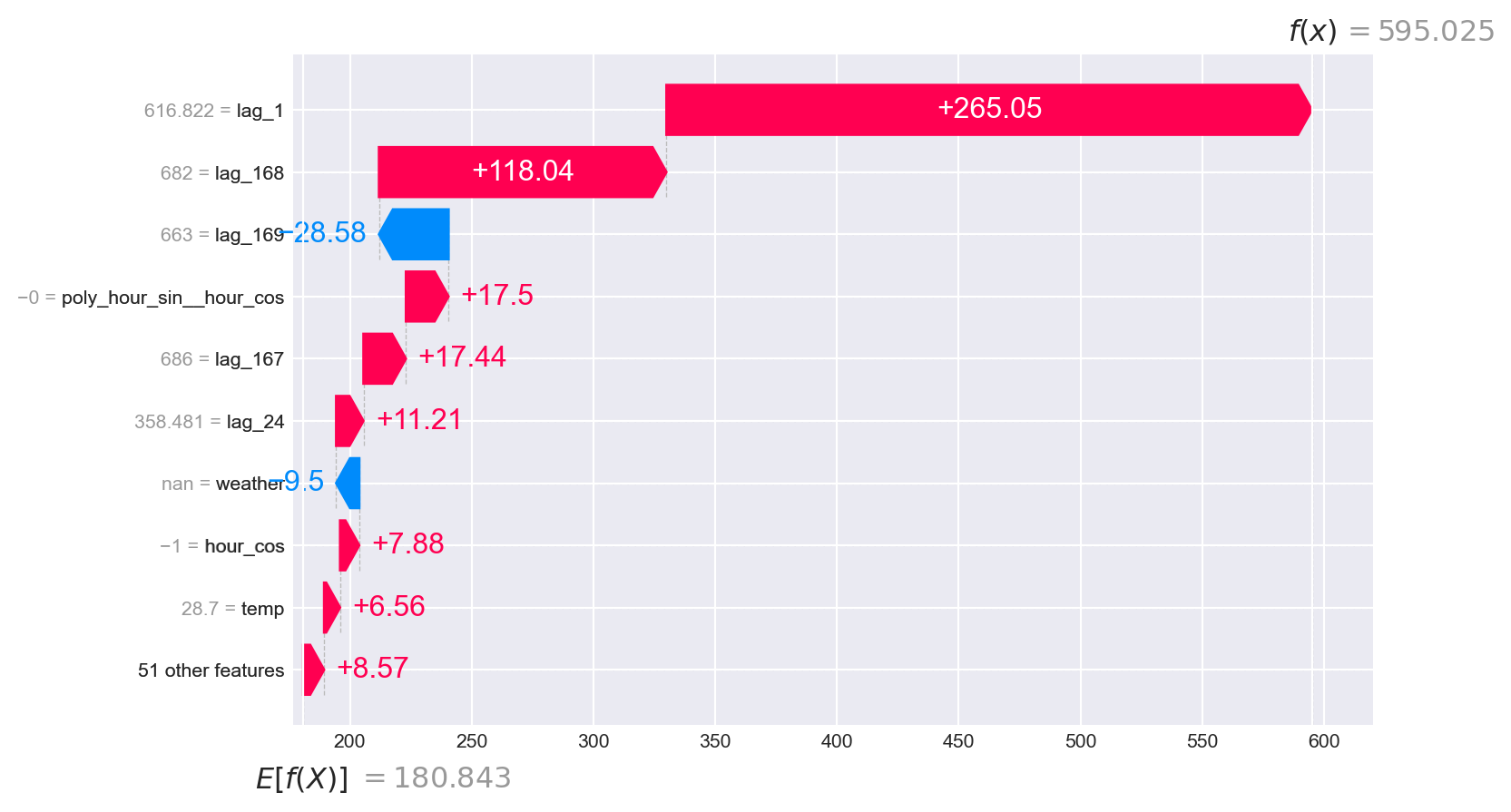
# Matrices de entrenamiento utilizadas por el forecaster para entrenar el regresor# ==============================================================================X_train, y_train = forecaster.create_train_X_y( y = datos.loc[:fin_validacion, 'users'], exog = datos.loc[:fin_validacion, exog_cols] )X_train.head(3)y_train.head(3)# Crear SHAP explainer (para modelos basados en árboles)# ==============================================================================explainer = shap.TreeExplainer(forecaster.regressor)# Se selecciona una muestra del 50% de los datos para acelerar el cálculorng = np.random.default_rng(seed=785412)sample = rng.choice(X_train.index, size=int(len(X_train)*0.5), replace=False)X_train_sample = X_train.loc[sample, :]shap_values = explainer.shap_values(X_train_sample)# Backtesting indicando que se devuelvan los predictores# ==============================================================================cv = TimeSeriesFold(steps =36, initial_train_size =len(datos.loc[:fin_validacion]))metrica, predicciones = backtesting_forecaster( forecaster = forecaster, y = datos['users'], exog = datos[exog_cols], cv = cv, metric ='mean_absolute_error', return_predictors =True,)predicciones.head(3)# Waterfall para una predicción concreta# ==============================================================================predicciones = predicciones.astype(datos[exog_cols].dtypes) # Asegurar tiposiloc_predicted_date = predicciones.index.get_loc('2012-10-06 12:00:00')shap_values_single = explainer(predicciones.iloc[:, 2:])shap.plots.waterfall(shap_values_single[iloc_predicted_date], show=False)fig, ax = plt.gcf(), plt.gca()fig.set_size_inches(8, 5)ax_list = fig.axesax = ax_list[0]ax.tick_params(labelsize=8)ax.setplt.show()
# Force plot para una predicción concreta# ==============================================================================shap.force_plot( base_value = shap_values_single.base_values[iloc_predicted_date], shap_values = shap_values_single.values[iloc_predicted_date], features = predicciones.iloc[iloc_predicted_date, 2:],)
Visualization omitted, Javascript library not loaded!
Have you run `initjs()` in this notebook? If this notebook was from another
user you must also trust this notebook (File -> Trust notebook). If you are viewing
this notebook on github the Javascript has been stripped for security. If you are using
JupyterLab this error is because a JupyterLab extension has not yet been written.
XGBoost, CatBoost, HistGradientBoostingRegressor
Desde el éxito del Gradient Boosting como algoritmo de machine learning, se han desarrollado varias implementaciones. Además de LightGBM, otras tres muy populares son: XGBoost, CatBoost e HistGradientBoostingRegressor. Todas ellas son compatibles con skforecast.
Las siguientes secciones muestran cómo utilizar estas implementaciones para crear modelos de forecasting, haciendo hincapié en el uso de su soporte nativo para características categóricas. Esta vez se utiliza una estrategia de validación one-step-ahead para acelerar la búsqueda de hiperparámetros.
# Particiones utilizadas para la búsqueda de hiperparámetros y backtesting# ==============================================================================cv_search = OneStepAheadFold(initial_train_size =len(datos_train))cv_backtesting = TimeSeriesFold(steps =36, initial_train_size =len(datos[:fin_validacion]))
╭─────────────────────────── OneStepAheadValidationWarning ────────────────────────────╮│ One-step-ahead predictions are used for faster model comparison, but they may not ││ fully represent multi-step prediction performance. It is recommended to backtest the ││ final model for a more accurate multi-step performance estimate. ││││ Category : OneStepAheadValidationWarning ││ Location : C:\Users\WINDOWS ││ 11\Documents\.virtualenvs\r-tensorflow\lib\site-packages\skforecast\model_selection\ ││ _utils.py:693 ││ Suppress : warnings.simplefilter('ignore', category=OneStepAheadValidationWarning) │╰──────────────────────────────────────────────────────────────────────────────────────╯
Al crear un forecaster utilizando HistogramGradientBoosting, los nombres de las columnas categóricas deben especificarse durante la instanciación del regresor pasándolos como una lista al argumento categorical_feature.
# Codificación ordinal# ==============================================================================# Se utiliza un ColumnTransformer para transformar variables categóricas# (no numéricas) utilizando codificación ordinal. Las variables numéricas# no se modifican. Los valores missing se codifican como -1. Si se encuentra una# nueva categoría en el conjunto de test, se codifica como -1.categorical_features = ['weather']transformer_exog = make_column_transformer( ( OrdinalEncoder( dtype=int, handle_unknown="use_encoded_value", unknown_value=-1, encoded_missing_value=-1 ), categorical_features ), remainder="passthrough", verbose_feature_names_out=False,).set_output(transform="pandas")# Crear forecaster# ==============================================================================forecaster = ForecasterRecursive( regressor = HistGradientBoostingRegressor( categorical_features=categorical_features, random_state=123 ), lags =24, window_features = window_features, transformer_exog = transformer_exog)# Busqueda de hiperparámetros# ==============================================================================lags_grid = [48, 72, [1, 2, 3, 23, 24, 25, 167, 168, 169]]def search_space(trial): search_space = {'max_iter' : trial.suggest_int('max_iter', 300, 1000, step=100),'max_depth' : trial.suggest_int('max_depth', 3, 10),'learning_rate' : trial.suggest_float('learning_rate', 0.01, 1),'min_samples_leaf' : trial.suggest_int('min_samples_leaf', 1, 20),'l2_regularization' : trial.suggest_float('l2_regularization', 0, 1),'lags' : trial.suggest_categorical('lags', lags_grid) } return search_spaceresults_search, frozen_trial = bayesian_search_forecaster( forecaster = forecaster, y = datos.loc[:fin_validacion, 'users'], exog = datos.loc[:fin_validacion, exog_cols], cv = cv_search, search_space = search_space, metric ='mean_absolute_error', n_trials =20)# Backtesting con datos de test# ==============================================================================metrica_histgb, predicciones = backtesting_forecaster( forecaster = forecaster, y = datos['users'], exog = datos[exog_cols], cv = cv_backtesting, metric ='mean_absolute_error', n_jobs =1)metrica_histgb
╭─────────────────────────── OneStepAheadValidationWarning ────────────────────────────╮│ One-step-ahead predictions are used for faster model comparison, but they may not ││ fully represent multi-step prediction performance. It is recommended to backtest the ││ final model for a more accurate multi-step performance estimate. ││││ Category : OneStepAheadValidationWarning ││ Location : C:\Users\WINDOWS ││ 11\Documents\.virtualenvs\r-tensorflow\lib\site-packages\skforecast\model_selection\ ││ _utils.py:693 ││ Suppress : warnings.simplefilter('ignore', category=OneStepAheadValidationWarning) │╰──────────────────────────────────────────────────────────────────────────────────────╯
Desafortunadamente, la versión actual de skforecast no es compatible con el manejo nativo de varaibles categóricas de CatBoost. El problema surge porque CatBoost sólo acepta variables categóricas codificadas como enteros, mientras que skforecast convierte los datos de entrada a float para utilizar matrices numpy y así acelerar el proceso. Para evitar esta limitación, es necesario aplicar one-hot encoding o label encoding a las variables categóricas antes de utilizarlas con CatBoost.
╭─────────────────────────── OneStepAheadValidationWarning ────────────────────────────╮│ One-step-ahead predictions are used for faster model comparison, but they may not ││ fully represent multi-step prediction performance. It is recommended to backtest the ││ final model for a more accurate multi-step performance estimate. ││││ Category : OneStepAheadValidationWarning ││ Location : C:\Users\WINDOWS ││ 11\Documents\.virtualenvs\r-tensorflow\lib\site-packages\skforecast\model_selection\ ││ _utils.py:693 ││ Suppress : warnings.simplefilter('ignore', category=OneStepAheadValidationWarning) │╰──────────────────────────────────────────────────────────────────────────────────────╯
Utilizar modelos Gradient Boosting en problemas de forecasting es muy sencillo gracias a las funcionalidades ofrecidas por skforecast.
Como se ha mostrado en este documento, la incorporación de variables exógenas como predictores puede mejorar en gran medida la capacidad predictiva del modelo.
Las variables categóricas pueden incluirse facilmente como variables exógenas sin necesidad de preprocesamiento. Esto es posible gracias al soporte nativo para variables categóricas ofrecido por LightGBM, XGBoost y HistGradientBoostingRegressor.